TeraPadはフリーで気軽に使えるエディタです。 文字コード UTF-8 の文書を扱うことができます。
以前の版とは違い、 最新版では文字コードがUTF-8のファイルも自動判別できるようになっていますので、 最新版のインストールをお勧めします(Ver.0.73→Ver.0.80で確認)。
設定は「表示」メニューの「オプション」から行います。
ファイルを保存するとき、 ファイル読み込み時の漢字コードで保存してくれないと、 いちいち保存したい漢字コードを指定しなくてはならず不便です。 TeraPadの設定を変更すると、問題が解決します。
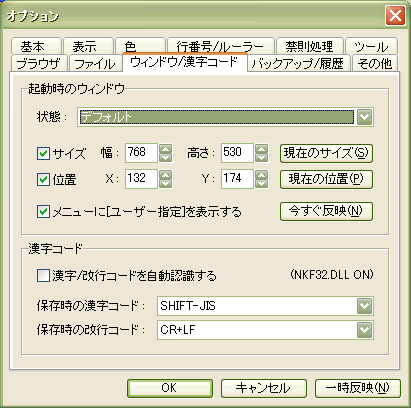
「ウインドウ/漢字コード」タブをクリックします。
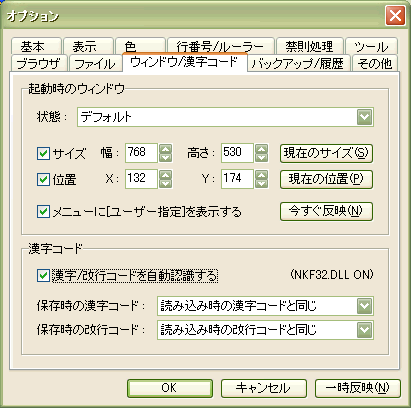
「漢字/改行コードを自動認識する」をチェックしておきます。 チェックしても UTF-8 は自動判別されませんが、 UNIX環境からファイルをコピーしてきたときに役立ちます。
「保存時の漢字コード」を「読み込み時の漢字コードと同じ」、 「保存時の改行コード」を「読み込み時の改行コードと同じ」とします。 この設定により、UTF-8 を指定して読み込み直したファイルは、 普通に上書き保存をすれば UTF-8 のままで保存されるようになります。
「表示」タブを選択し、「全角空白マーク」にチェックをしておくと、 全角空白が淡い色の□で表示されるようになります。 XMLやJavaのソースファイルに混入した全角空白が発見しやすくなり、 課題が早く終わります。