前回までで学んだリストは順序づけられたデータの並びを表現するために用いる データ構造であった。今回は、階層化されたデータを表現するデータ構造である 木 (tree) について学ぶ。
木は、多くのアルゴリズムで中心的な役割を果たす重要なデータ構造である。 データ構造以外にも、一般にものごとの解析する場合や問題の解き方を考える 上でも木の概念は重要である。これは、ものごとが次々と枝分かれしていく 様子を表現するのに木が最も適しているからである。
今回は、データ構造としての木の基礎的な部分を扱う。
教科書 pp.328- 参照。 ここで扱う木とは、教科書の Fig 10-1 のような構造のことである。 図の丸で表したものそれぞれをノード (node, あるいは 頂点 (vertex), 節 (せつ) とも言う) と呼ぶ。
ノードとノードの間に親子関係を定義し、枝 (branch edgeまたは単に edge、辺とも言う) と呼ぶ線で結ぶ。 ノードの中の最も根元のように見える一つを根 (root) と呼び、 最も枝分かれの先にあるように見えるノードを葉と呼ぶ。 枝の上側 (根元側) のノードが親 (parent) 、 下側のノードが子 (child) である。 根以外のノードには一つだけ親があるが、子の数には制限はない (子を持たなくても良い)。
実世界には、木で表せるものごとが多い。
教科書 pp.328-329を参照し、 少なくとも次の言葉の意味は理解しよう。
教科書 p.332 参照。 各ノードの子の数が2以下であるような木を2分木と呼ぶ。 2分木はさまざまなアルゴリズムで利用される頻度が最も大きい。
データ構造として木を使う場合は、各ノードにデータを置き、 枝を参照で表すのが普通である。Java で2分木のノードを表現する クラス BinNode は次のように定義することができる。
public class BinNode {
int key;
String value;
BinNode left, right;
public BinNode() { }
public BinNode(int key, String value, BinNode left, BinNode right) {
this.key = key;
this.value = value;
this.left = left;
this.right = right;
}
public BinNode(int key, String value) {
this.key = key;
this.value = value;
this.left = null;
this.right = null;
}
public int getKey() { return key; }
public void setKey(int key) {
this.key = key;
}
public String getValue() { return value; }
public void setValue(String value) {
this.value = value;
}
public BinNode getLeft() { return left; }
public void setLeft(BinNode left) {
this.left = left;
}
public BinNode getRight() { return right; }
public void setRight(BinNode right) {
this.right = right;
}
public void print() {
System.out.println(key + ": " + value);
}
}
変数 left と right がこのノードに対する子ノードへの参照である。 子がいないときは null とする。
なお、このプログラムではノードにキーとそれに対応する値からなる データのかたまりを置くこととしている。 このかたまりのことをレコード (record) と言う。 そして、キーを指定して、それと等しいキーのデータを選び出すことを探索と言う。 例えば、住所録の例では、人物の読み仮名がキーで、 対応する値は住所に関するさまざまな情報である。 今回は簡単化のため、キーを整数値、対応する値を文字列としている。
ここでは、木の中のキーはすべて違うものと考える。 同じキーが重複して登録することは禁止される。 重複登録を可能にするには、ここでのアルゴリズムとは別の工夫が必要であるが、 本質的ではないので割愛する。
クラス BinNode とは別の場所に木の根を表す変数 root を用意しておく。 木に対する操作はもっぱらこの root を出発点として行う。表が空のときの root の値は null である。
教科書 pp.330-331 参照。 一定の規則に従い、木のすべてのノードを訪問することを走査 (traverse) と言う。走査の方法は大きく分けて2つの方法がある。
各手法についての説明は教科書 p.331 の説明を参照のこと。 ここでは、プログラムの例を示す。
void preorder(BinNode p) {
if (p == null) return;
pに関する処理;
preorder(p.getLeft());
preorder(p.getRight());
}
引数 p が走査の対象となるノードを指す。 ノード p 自身に関する処理を行ってから、 左右の子に対してメソッド preorder を再帰的に呼び出す。 この手続きを preorder(root) の形で呼び出せば、 木全体をたどることができる。
間順走査、降順走査についても手続き自体の形はほとんど同じである。
void inorder(BinNode p) {
if (p == null) return;
inorder(p.getLeft());
pに関する処理;
inorder(p.getRight());
}
void postorder(BinNode p) {
if (p == null) return;
postorder(p.getLeft());
postorder(p.getRight());
pに関する処理;
}
これまでのリストを用いた探索では、 常に先頭からノードをたどり、すべてのノードのキーを調べる必要があった。
今後は、等しいかどうかだけではなく、大小の判定を使って探索を行うことを考えよう。 データを大小関係に基づいて規則を決めて並べておけば、 探索の対象のデータとキー1個と比較して、対象のデータの方がキーより小さければ、 それより大きなキーを持つノードはもはや考慮の対象としなくて良い。 これによって、比較しなければならないキーの個数を大幅に減らすことができる。
この考え方を用いた木の構成方法の1つが2分探索木 (binary search tree) である。 (教科書 pp.333-347) (リストや配列を使う方法に2分探索 (binary search) がある。 これは2分探索木とは別の方法である。)
2分木のノードに1つずつデータを入れたものを考える。 このときある頂点から見て、以下の条件を満たす木を2分探索木と呼ぶ。
2分探索木の例は教科書 p.333 Fig.10-8 に掲載されている。 根の左側の子孫の値はすべて 10 より小さく、 右側の子孫の値は 10 より大きい。
データの集合を表す2分木の形は一とおりとは限らない。 例えば、1,2,3の3つの値からなる木の形は次のように5とおりある。
(2) (1) (1)
/\ \ \
/ \ \ \
(1) (3) (2) (3)
\ /
\ /
(3) (2)
(3) (3)
/ /
/ /
(1) (2)
\ /
\ /
(2) (1)
実際にどの表現になるかは、木を作る際の手順によって決まるのが普通である。 また、これらの表現の間には性能面の違いがある。
教科書p.338参照。 探索は、根から葉の方向に順次降りていきながら行う。 各ノードでは以下のことを行う。
これをプログラムとして書くことを考えてみよう。
この手続きは探索と同じ考え方で書くことができる。
これをプログラムとして書くことを考えてみよう。
2分探索木では、探索の計算量は木の形によって大きく変わる。
探索の計算量は、根から目標のノードに至るまでに調べるノードの数にほぼ比例する。 探索されるキーに偏りがないとすると、各ノードの深さをできるだけ同じにしておくのが良い。 計算量の点で理想的なのは、根から葉までの距離がどこでも等しくなっている木である。 このような木を完全2分木 (complete binary tree) と言う。
( ) / \ / \ / \ / \ / \ ( ) ( ) / \ / \ / \ / \ () () () () /\ /\ /\ /\ / \ / \ / \ / \ () ()() ()() ()() ()
ノードの個数が 2d - 1 の完全2分木を探索する際に調べる頂点の数は、 ほぼ d-1 個に等しいことが知られている。よって、ノードの個数を n 個とした場合、 log n 個のデータと比較するだけで良いことになる。なお、2分木をはじめとする、 問題を2つに分割しながら解いていくようなアルゴリズムを評価する際の log の底は たいがい2である。
ここまでで、最善の場合は O(log n) だとわかった。 一方、一般的な平均計算量は、n が十分大きくなると、1.39 log n に近づくことが知られている。 理想的な場合に比べて 1.39 倍しか悪くなっていないので、 結論として2分探索木の探索に要する平均の計算量は、やはり O(log n) である。
ノードの挿入も、基本的なやり方は探索と同様なので計算量は O(log n) である。
2分探索木からデータを削除する方法を示す。 まず、削除するノードを探す。このノードについて 以下の3とおりに分けて考える。
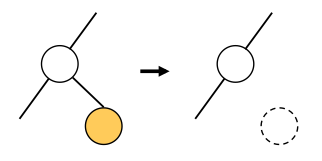
ノードを単に取り除いて、このノードを指す親から参照を null で置き換えれば良い。
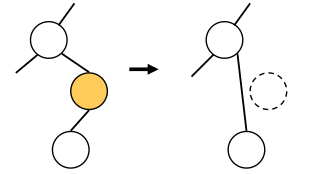
ノードを取り除き、このノードの代わりに削除ノードの子を置く。 削除ノードの親から見ると、今まで孫だったノードが 子に変わるということである。
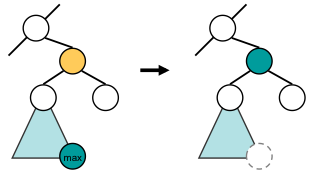
削除するノードの左右両方の子がある場合は少し複雑である。 削除するノードから見て左側の部分木の最大の要素 (右側の部分木の最小の要素でも同じ) をこのノードの代役にする という方法をとる。
2分探索木の構築と、 木のさまざまな機能 (データの追加、探索、木全体の表示) を 1つのクラスとして実装しなさい。 1つのノードを表すクラスには、このテキストの冒頭で示した BinNode クラスを使う。 Java クラスライブラリのTreeMap の機能縮小版を自分で作ると考えれば良い。
クラス名は BST とする。(提出ファイル名 BST.java) 次のような機能を持つこととする。
81: Japan
39: Italy
1: USA
44: UK
91: India
82: South Korea
886: Taiwan
次のようなメソッド main で動作を確認すること。 キーは国際電話の国番号、値は国名である。
public class BSTMain {
public static void main(String[] args) {
BST tree = new BST();
tree.add(81, "Japan");
tree.add(39, "Italy");
tree.add(44, "UK");
tree.add(1, "USA");
tree.add(91, "India");
tree.add(82, "South Korea");
tree.add(886, "Taiwan");
tree.preorderPrint();
System.out.println("[探索テスト]");
BinNode node;
System.out.print("国番号44の国は ");
node = tree.search(44);
if (node != null)
System.out.println(node.getValue());
else
System.out.println("見つかりません");
System.out.print("国番号99の国は "); /* 見つからないはず */
node = tree.search(99);
if (node != null)
System.out.println(node.getValue());
else
System.out.println("見つかりません");
System.out.println("[削除テスト]");
tree.remove(81);
tree.remove(39);
tree.remove(886);
System.out.println("44, 1, 91, 82だけ残っていればok");
tree.preorderPrint();
}
}
クラスBSTの大枠は次のようになる。 ソース中のコメントにヒントを記してあるので、プログラミングの助けにすると良い。
public class BST {
BinNode root;
public BST() {
root = null;
}
// 再帰呼び出しを行うメソッドsearchを呼び出す
public BinNode search(int key) {
return search(key, root);
}
// 2分探索木の決まりに基づいて、再帰呼び出しを行いながらノードを辿り、
// 目的のノードを探して返す 見つからなかったらnullを返す
private BinNode search(int key, BinNode p) {
if (p == null)
return null;
// ここを考える
}
// 木に一つもノードが存在しないときはrootが新たな追加ノードを指すようにし、
// すでにノードがあるときは再帰呼び出しを行うメソッドaddを呼び出す
public void add(int key, String value) {
if (root == null)
root = new BinNode(key, value);
else
add(root, key, value);
}
// 再帰呼び出しを行いながらノードを辿り、
// 挿入すべき位置に達したならば、そこにノードを追加する
private void add(BinNode p, int key, String value) {
// ここを考える
}
public void preorderPrint() {
preorderPrint(root, 0);
}
private void preorderPrint(BinNode p, int depth) {
if (p == null) return;
for (int i = 0; i < depth; i++)
System.out.print(" ");
p.print();
preorderPrint(p.getLeft(), depth + 1);
preorderPrint(p.getRight(), depth + 1);
}
public void remove(int key) {
remove(root, null, key);
}
// 削除するか調べる対象のノードpと、その親ノードparent、削除したいデータkeyを引数に受け取り、
// 目的のノードに達するまで再帰呼び出しを行う
// 削除すべきノードが見つかった場合、
// 1) 削除ノードに子がいない
// 2) 削除ノードの右だけに子がいる
// 3) 削除ノードの左だけに子がいる
// 4) 削除ノードの左右に子がいる
// の4パターンに分けて処理を行う
public void remove(BinNode p, BinNode parent, int key) {
if (p == null)
System.out.println("キー: " + key + " が見つかりません" );
else if (key < p.getKey())
remove(p.getLeft(), p, key);
else if (key > p.getKey())
remove(p.getRight(), p, key);
else { // 削除するノードp がみつかった
if (p.getLeft() == null && p.getRight() == null ) { // pの子がいないとき
if (parent == null) // pが根のとき
root = null;
else // pが根ではないとき
if (parent.getLeft() != null &&
key == parent.getLeft().getKey())
parent.setLeft(null);
else
parent.setRight(null);
}
else if (p.getLeft() == null) { // pの右だけに子がいるとき
if (parent == null) // pが根のとき
root = p.getRight();
else // pが根ではないとき
if (parent.getLeft() != null &&
key == parent.getLeft().getKey())
parent.setLeft(p.getRight());
else
parent.setRight(p.getRight());
}
else if (p.getRight() == null) { // pの左だけに子がいるとき
if (parent == null) // pが根のとき
// ここを考える
else // pが根ではないとき
// ここを考える
}
else { // pの左右両方に子がいるとき
// ここを考える (下の2つのメソッドを利用して書くと良い)
// 行うべきこと:
// 1. pの左部分木の中の最大のノードを leftMax と置く
// 2. leftMax の中身を p にコピーする (元の p の中身は上書きされて消える)
// 3. pの左部分木からleftMaxを削除する
}
}
}
// p 以下の部分木から最大のキーを持つノードを探す
private BinNode getMax(BinNode p) {
if (p.getRight() == null)
return p;
else
return getMax(p.getRight());
}
// p 以下の部分木から最大のキーを持つノードを削除し、
// この部分木の新たな根となるノードを返す
private BinNode removeMax(BinNode p) {
if (p.getRight() == null)
return p.getLeft();
else {
p.setRight(removeMax(p.getRight()));
return p;
}
}
}